The Kafka consumer groups concept is a great and easy-to-approach abstraction over multi-instance consumption of records from topics. In certain cases, however, you might end up with a scenario where only a subset of all consumers in a group is assigned to any partitions. As a result, the balanced spread of partitions amongst consumers one would expect, is not happening. In this post I will describe the consumer group partition assignment process and why it matters.
It should be noted that this post is written on the basis of the current “Stop-The-World”. While KIP-429 will bring incremental rebalance, the contents of this post should still be valid with the proposed changes.
Consumer Group Scenario
Consider a topic-partition setup with a consumer group (g0), where each consumer in the group subscribes to (t0, t1) (disregard replication factor):
What assignment of partitions (or more importantly, how much spread / utilization of consumers) would you expect in this case?
With 8 partitions in total and 10 consumers, a fair guess might be that 8 consumers are assigned to one partition each, leaving 2 idle. However, as most seem to find out after working with Kafka for a while, this is not the case. Instead, with default settings, the assignment looks like this:
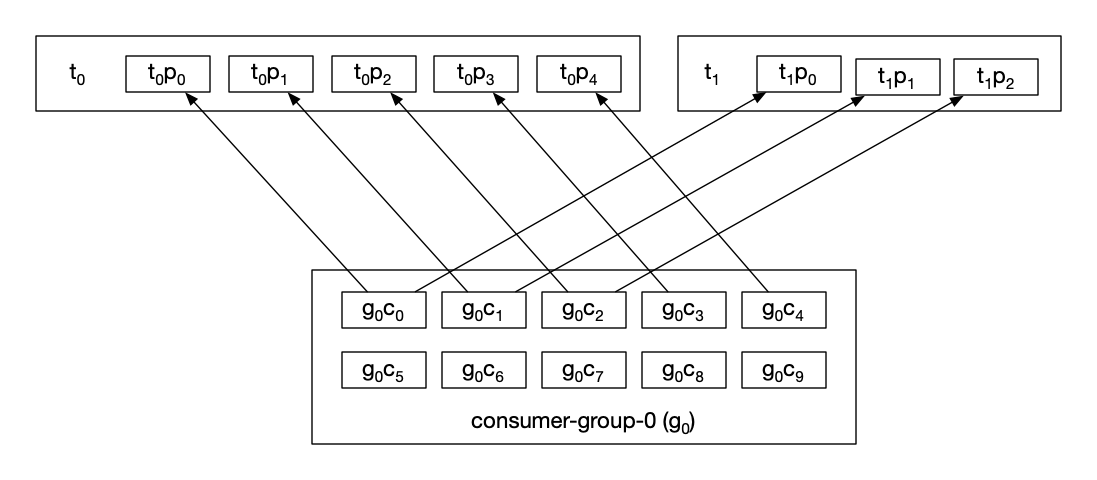
5 consumers are now idle, which can either be what you want.. or not. At the same time, 3 consumers are doing more work than the rest. The problem becomes even worse if the consumers subscribed to even more topics with few partitions.
Consumer Partition Assignment Strategies
Partition assignment is based on the strategy pattern where clients do the assignment rather than the server. One consumer is made the group leader (first consumer to send a JoinGroup request). During a rebalance, this consumer receives all the available consumers in the group and what each subscribes to. It is then up to that client to do the assignments. Once the assignments are made, the leader sends it back to the cluster (specifically the Group Coordinator for the group) which sends the specific assignments back to each consumer.
This approach has the benefit that you, as a user of Kafka, is able to plug in any partition assignment strategy you want (depending on the library you use, as we will see later). The cluster is not involved in any decision-making on what consumers get assigned what partitions.
In the Kafka Clients library for Java, the interface for implementing a strategy is PartitionAssignor. You specify which strategy to use by providing the implementation class FQN as the value for the config partition.assignment.strategy. The official Java library provides a few implementations, but the most notable ones are org.apache.kafka.clients.consumer.RangeAssignor and org.apache.kafka.clients.consumer.RoundRobinAssignor.
This is where the example above becomes a common case for Kafka adopters. The strategy defaults to the RangeAssignor implementation which works as follows (docs):
The range assignor works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumers in lexicographic order. We then divide the number of partitions by the total number of consumers to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.
This strategy assigns partitions per-topic to a sorted list of consumers. This is what causes the partitions to not be uniformly distributed in our example.
As a consequence, given a set of n topics and a set of m consumers in the group and all consumers subscribe to all you will topics, at most z consumers will be assigned to work where z is the max partitions of all the topics. If m > z this leaves m - z idle consumers.
The RoundRobinAssignor does as you might expect from the name (docs):
The round robin assignor lays out all the available partitions and all the available consumers. It then proceeds to do a round robin assignment from partition to consumer. If the subscriptions of all consumer instances are identical, then the partitions will be uniformly distributed. (i.e., the partition ownership counts will be within a delta of exactly one across all consumers.)
Community Based Versions
While the official Java based Kafka library provides a set of assignment strategies (at the time of writing, five are provided), you should be aware of what is available (and what isn’t) for the specific client library you use.
This is a non-exhaustive list of community based client libraries and their supported strategies:
- kafka-node
- Strategies: round-robin, range
- Default: round-robin
- Custom: yes
- KafkaJS
- Strategies: round-robin
- Custom: yes
- C# / confluent-kafka-dotnet (or any librdkafka based)
- Strategies: round-robin, range
- Default: round-robin
- Custom: no
- kafka-python
- Strategies: round-robin, range
- Default: range
- Custom: yes
- sarama
- Strategies: range, round-robin, sticky
- Default: range
- Custom: no
Most provide both round-robin and range. Although these should cover the majority of cases, should you want to provide a custom implementation, make sure to check your options, and in general, be aware of what the defaults are.